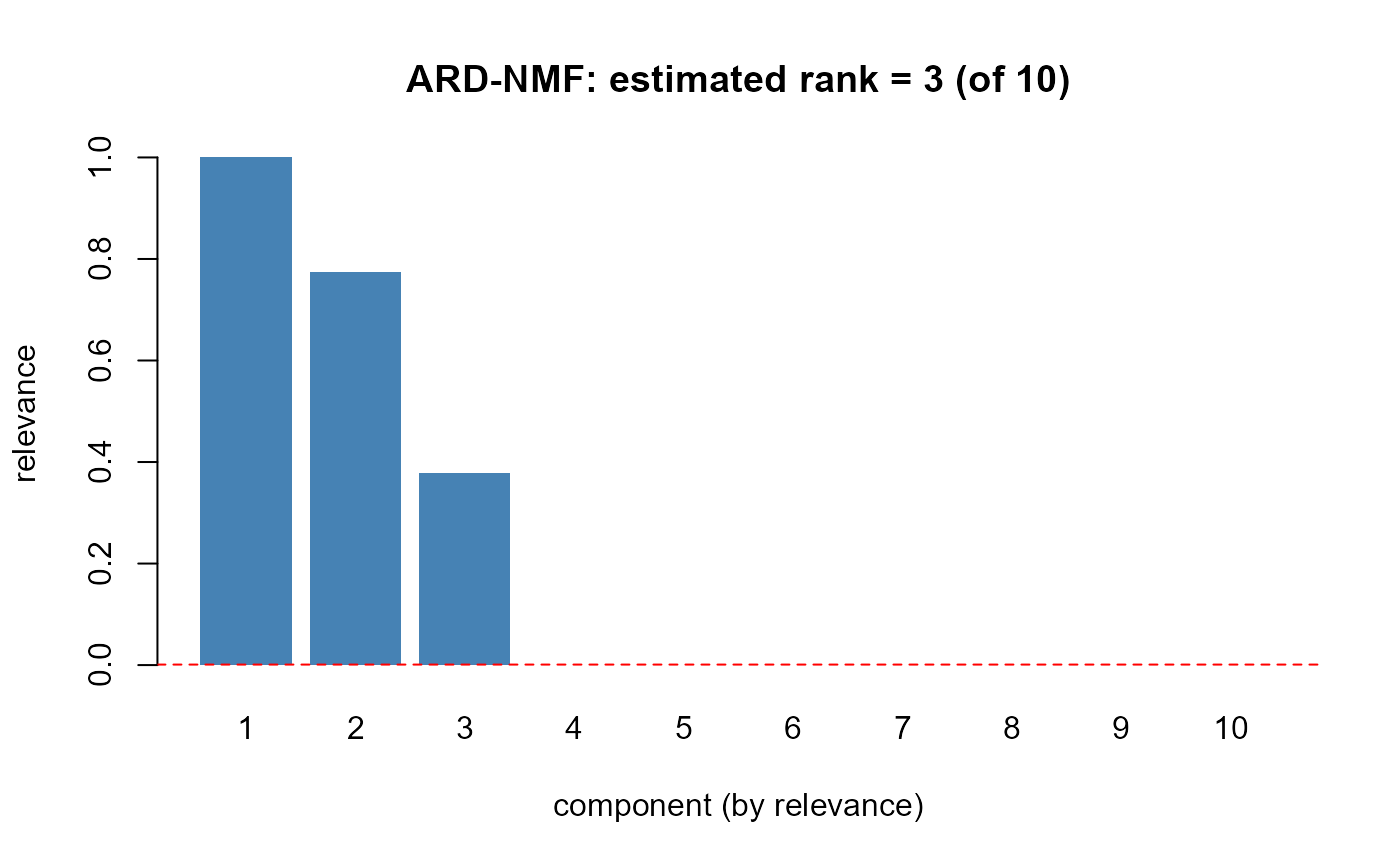
Prototype of Tan & Fevotte's (2013) ARD-NMF (Euclidean /
\(\beta = 2\)). Unlike the cross-validation (nmfkc.ecv,
nmfkc.bicv) and stability (nmfkc.consensus)
engines that scan a range of ranks, ARD fits NMF once at
an over-complete rank and prunes automatically: each component \(k\)
carries a relevance weight \(\lambda_k\) with an inverse-gamma prior;
the multiplicative updates gain a penalty \(+ w_{fk}/\lambda_k\) (L2 /
half-normal prior) or \(+ 1/\lambda_k\) (L1 / exponential), which
drives unsupported components to zero. The number of surviving
components is the estimated rank. Covariates are ignored (plain NMF).
This is a model-based point estimate: the result depends on the prior, the starting rank and the random initialization, and can vary run to run. Use it as a complement to the CV / consensus engines, not a sole criterion.
Arguments
- Y
Observation matrix (\(F \times N\)), non-negative.
- rank
Over-complete starting rank \(K\) (must exceed the true rank).
NULL(default) usesmin(F, N, 20).- nrun
Number of random-initialization restarts (default
10). ARD is a sensitive point estimate, so several restarts are advisable; the reported rank is the mode of the per-run estimates (rank.runs), with a representative modal fit kept forplot/W/H.- plot
Logical; draw the relevance bar plot.
- ...
Advanced options, rarely needed (defaults in parentheses):
prior("L2": half-normal / squared-energy group shrinkage,"L1": exponential / sparser);seed(123, random-initialization seed);a(1) andb((F + N)/K * mean(Y)), the inverse-gamma prior (a smallerbover-prunes, a larger one prunes nothing);maxit(3000) andepsilon(1e-6) for optimisation control;tol(1e-3), the relevance threshold below which a component is counted as pruned.
Value
An object of class "nmfkc.ard": a list with
rank (estimated = mode over restarts), rank.runs (the
per-run estimates), relevance (representative run, descending),
lambda, W, H (ordered by relevance),
rank.init, prior, nrun and objfunc.
Details
Relation to Tan & Fevotte (2013). The update equations reproduce
the paper's \(\ell_2\) / \(\ell_1\) ARD-NMF for the Euclidean
(\(\beta = 2\)) case exactly: the multiplicative penalties, the
closed-form \(\lambda_k\) update \((f(w_k) + f(h_k) + b)/c\) and the
constant \(c\) (their Eq. 33). Two deliberate simplifications keep it
practical: only \(\beta = 2\) is implemented (the paper covers the general
\(\beta\)-divergence), and the default b is an empirical
per-component energy scale \((F + N)/K \cdot \bar{Y}\) that reliably avoids
the winner-take-all collapse, rather than the paper's method-of-moments value
(their Eq. 38).
References
V. Y. F. Tan and C. Fevotte (2013). Automatic relevance determination in nonnegative matrix factorization with the beta-divergence. IEEE TPAMI 35(7):1592–1605. doi:10.1109/TPAMI.2012.240 .