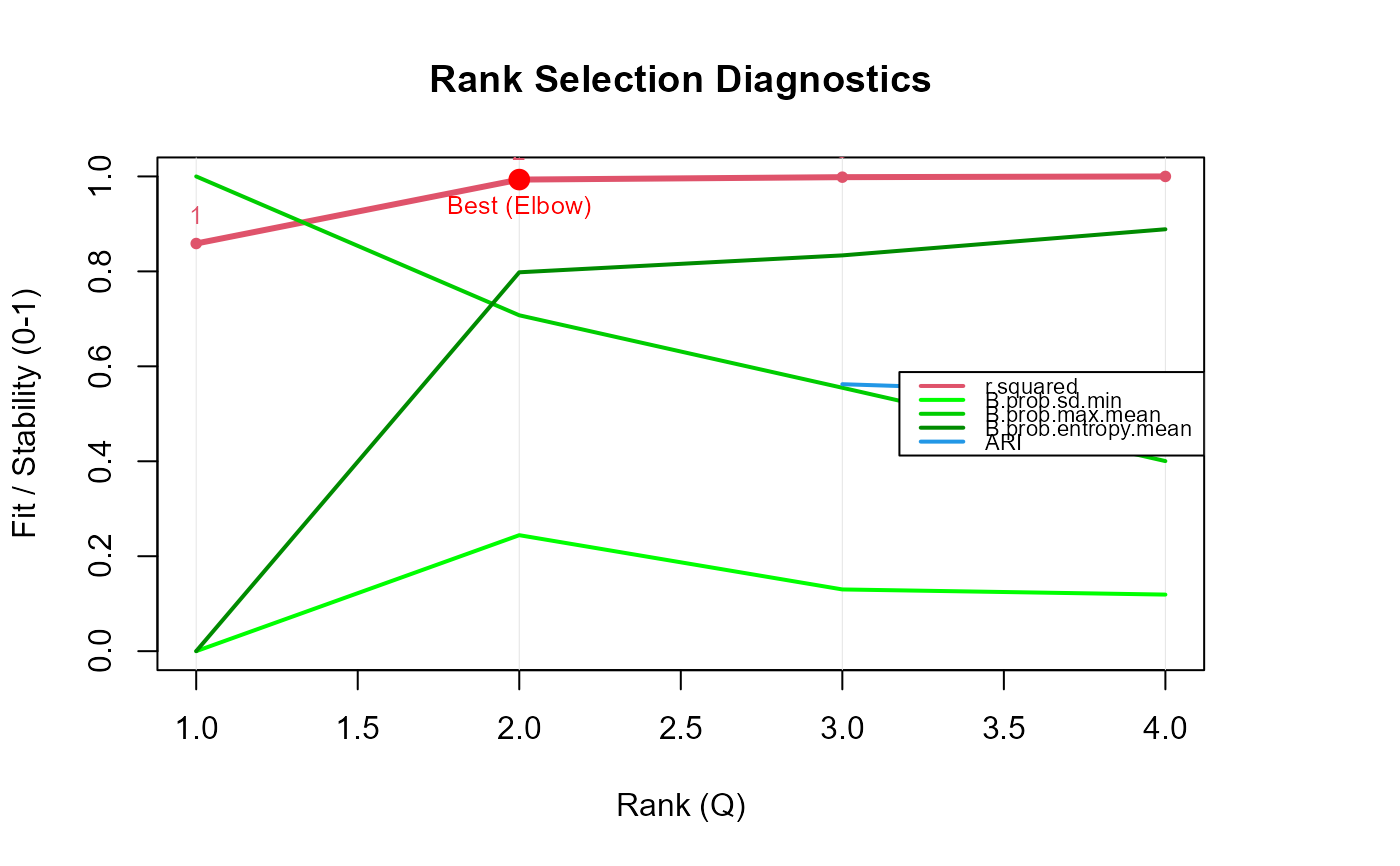
nmfkc.rank provides diagnostic criteria for selecting the rank (\(Q\))
in NMF with kernel covariates. Three rank-selection measures are computed
(R-squared, the effective rank, and the element-wise CV error), and results
can be visualized in a plot. Sample-clustering quality (silhouette / CPCC /
dist.cor) is no longer part of rank selection; use nmf.cluster.criteria
on a fitted model for those.
By default (save.time = FALSE), this function also computes the
Element-wise Cross-Validation error (Wold's CV Sigma) using nmfkc.ecv.
The plot explicitly marks the "BEST" rank based on two criteria:
Elbow Method (Red): Based on the curvature of the R-squared values (always computed if Q > 2).
Min RMSE (Blue): Based on the minimum Element-wise CV Sigma (only if
detail="full").
Arguments
- Y
Observation matrix, or a formula (see
nmfkcfor Formula Mode).- A
Covariate matrix. If
NULL, the identity matrix is used. Ignored whenYis a formula.- rank
A vector of candidate ranks to be evaluated.
- detail
"full"(default) also runs the element-wise CV (sigma.ecv);"fast"skips it (the plot then shows only r.squared and eff.rank, and the recommended rank falls back to the R-squared elbow).- plot
Logical. If
TRUE(default), draws a plot of the diagnostic criteria.- data
A data frame (required when
Yis a formula with column names).- ...
Additional arguments passed to
nmfkcandnmfkc.ecv.Q: (Deprecated) Alias forrank.save.time: (Deprecated)TRUEmaps todetail = "fast".
Value
A list containing:
- rank.best
The estimated optimal rank. Prioritizes ECV minimum if available, otherwise R-squared Elbow.
- criteria
A data frame containing diagnostic metrics for each rank. The
effective.rankcolumn gives the effective rank (\(\exp\) of the Shannon entropy of the explained-variance distribution \(p_k = \mathrm{var}(B_{k\cdot}) / \sum_j \mathrm{var}(B_{j\cdot})\), in \([1, Q]\)); when it plateaus well below the nominalrank, the extra factors are not carrying additional coefficient variance, which suggests an over-specified rank. Theeffective.rank.ratiocolumn iseffective.rank / rankin \([0, 1]\) (the utilization fraction plotted aseff.rankwhenplot = TRUE); a peak marks the rank at which the latent factors carry the most evenly distributed variance.
References
Roy, O., & Vetterli, M. (2007). The effective rank: A measure of
effective dimensionality. Proc. 15th European Signal Processing
Conf. (EUSIPCO), 606–610. (effective.rank)
Wold, S. (1978). Cross-validatory estimation of the number of
components in factor and principal components models.
Technometrics, 20(4), 397–405.
doi:10.1080/00401706.1978.10489693
(sigma.ecv)
See also
nmfkc,
nmfkc.ecv (element-wise CV, used internally),
nmfkc.bicv (block bi-cross-validation),
nmfkc.consensus (stability) and
nmfkc.ard (Bayesian ARD) for alternative rank criteria.
Examples
# Example.
Y <- t(iris[,-5])
# Full run (default)
nmfkc.rank(Y, rank=1:4)
#> Y(4,150)~X(4,1)B(1,150)...
#> 0sec
#> Y(4,150)~X(4,2)B(2,150)...
#> 0sec
#> Y(4,150)~X(4,3)B(3,150)...
#> 0sec
#> Y(4,150)~X(4,4)B(4,150)...
#> 0sec
#> Running Element-wise CV (this may take time)...
#> Performing Element-wise CV for Q = 1,2,3,4 (5-fold)...
#> Note: sample-clustering quality (silhouette / CPCC / dist.cor) is not part of rank selection; compute it from a list of fits with nmf.cluster.criteria(). See ?nmf.cluster.criteria
 # Fast run (skip ECV)
nmfkc.rank(Y, rank=1:4, detail="fast")
#> Y(4,150)~X(4,1)B(1,150)...
#> 0sec
#> Y(4,150)~X(4,2)B(2,150)...
#> 0sec
#> Y(4,150)~X(4,3)B(3,150)...
#> 0sec
#> Y(4,150)~X(4,4)B(4,150)...
#> 0sec
#> Note: sample-clustering quality (silhouette / CPCC / dist.cor) is not part of rank selection; compute it from a list of fits with nmf.cluster.criteria(). See ?nmf.cluster.criteria
# Fast run (skip ECV)
nmfkc.rank(Y, rank=1:4, detail="fast")
#> Y(4,150)~X(4,1)B(1,150)...
#> 0sec
#> Y(4,150)~X(4,2)B(2,150)...
#> 0sec
#> Y(4,150)~X(4,3)B(3,150)...
#> 0sec
#> Y(4,150)~X(4,4)B(4,150)...
#> 0sec
#> Note: sample-clustering quality (silhouette / CPCC / dist.cor) is not part of rank selection; compute it from a list of fits with nmf.cluster.criteria(). See ?nmf.cluster.criteria